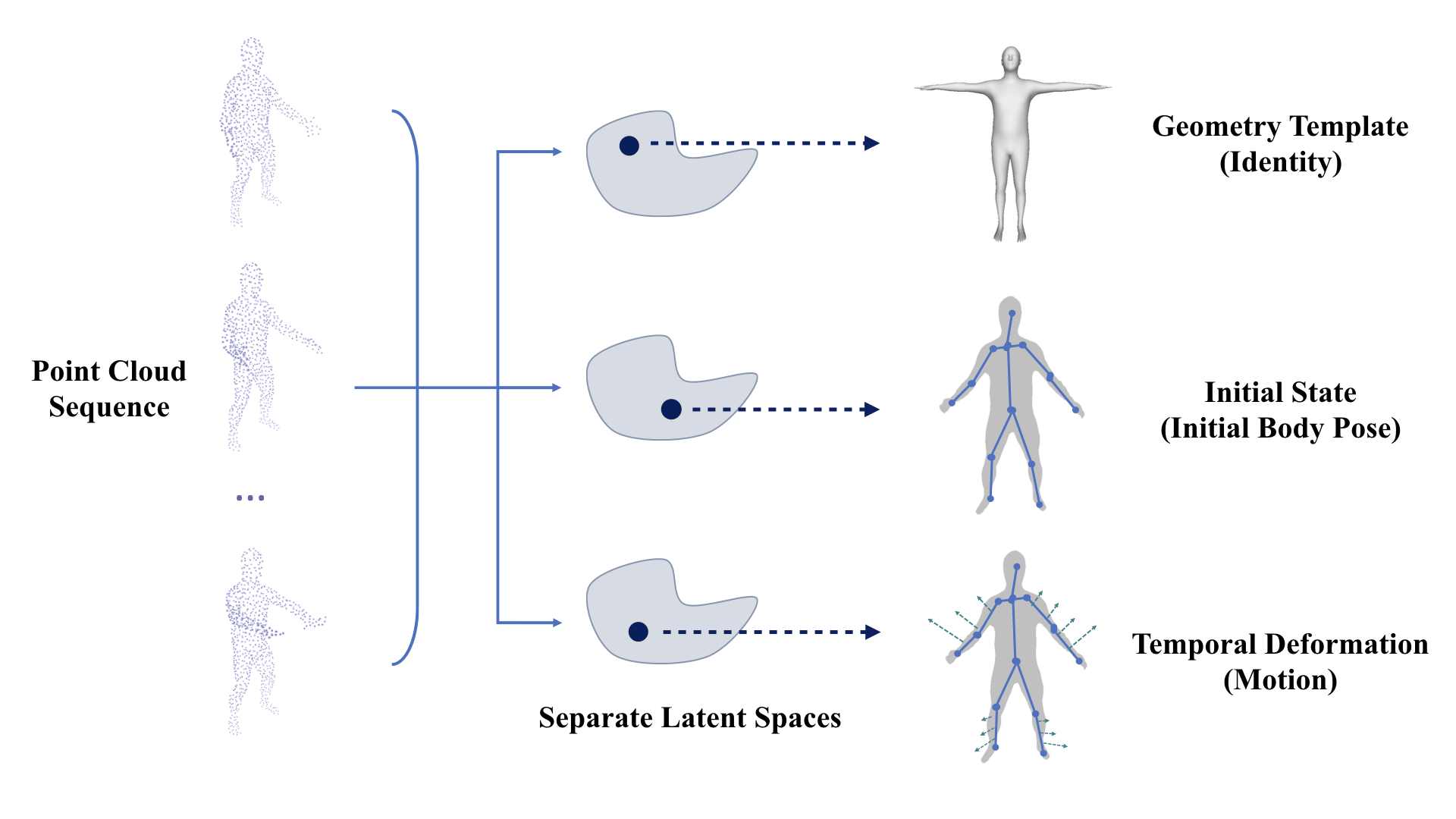
Overview of Our 4D Compositional Representation.
|
Fudan University Google
|
|
Overview of Our 4D Compositional Representation.
|
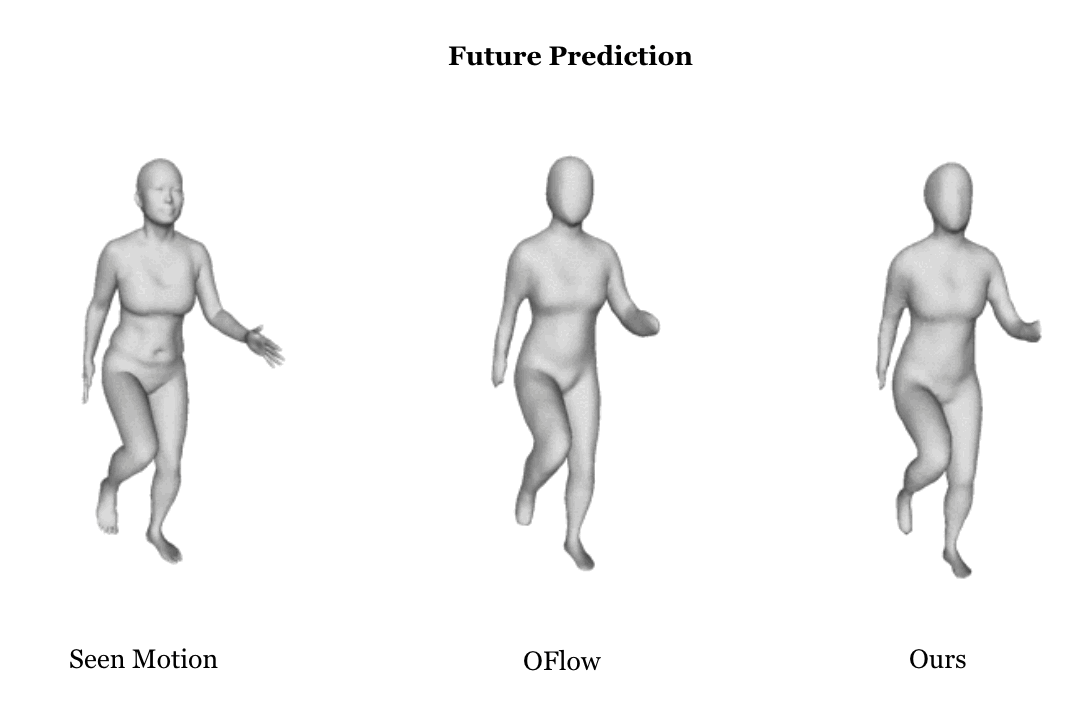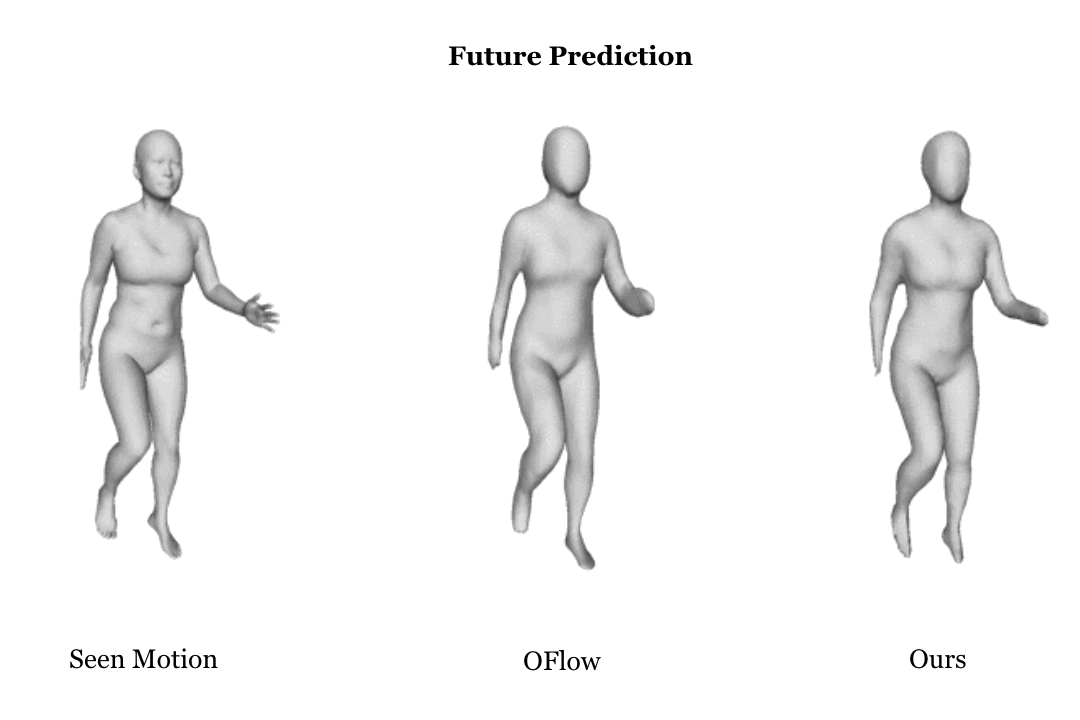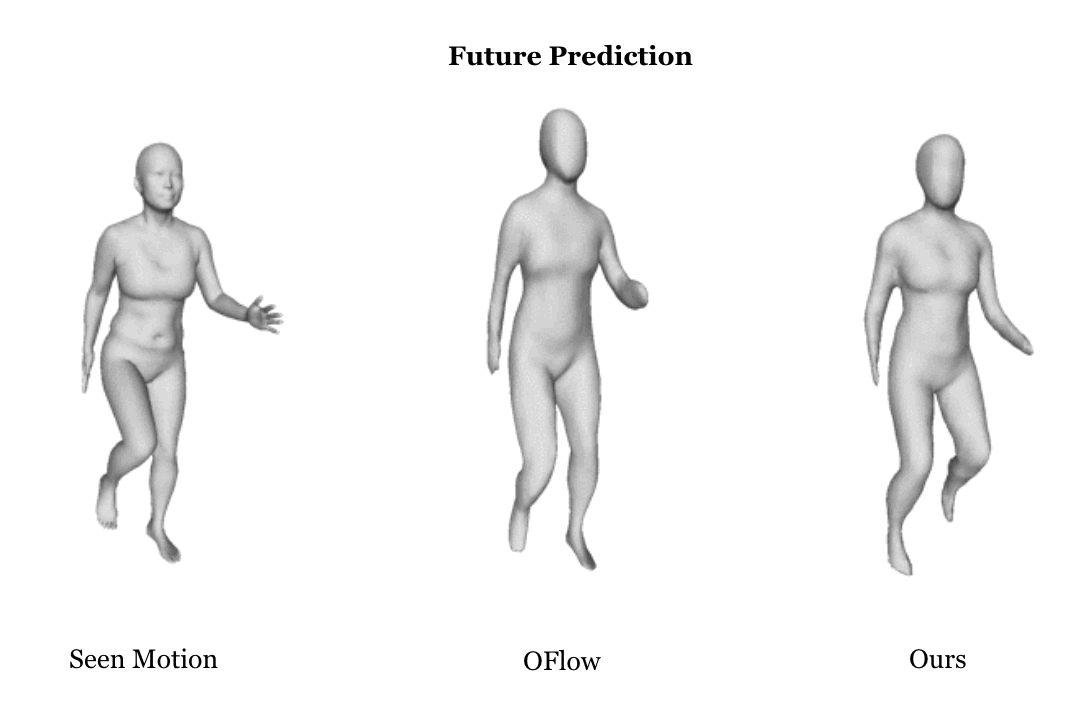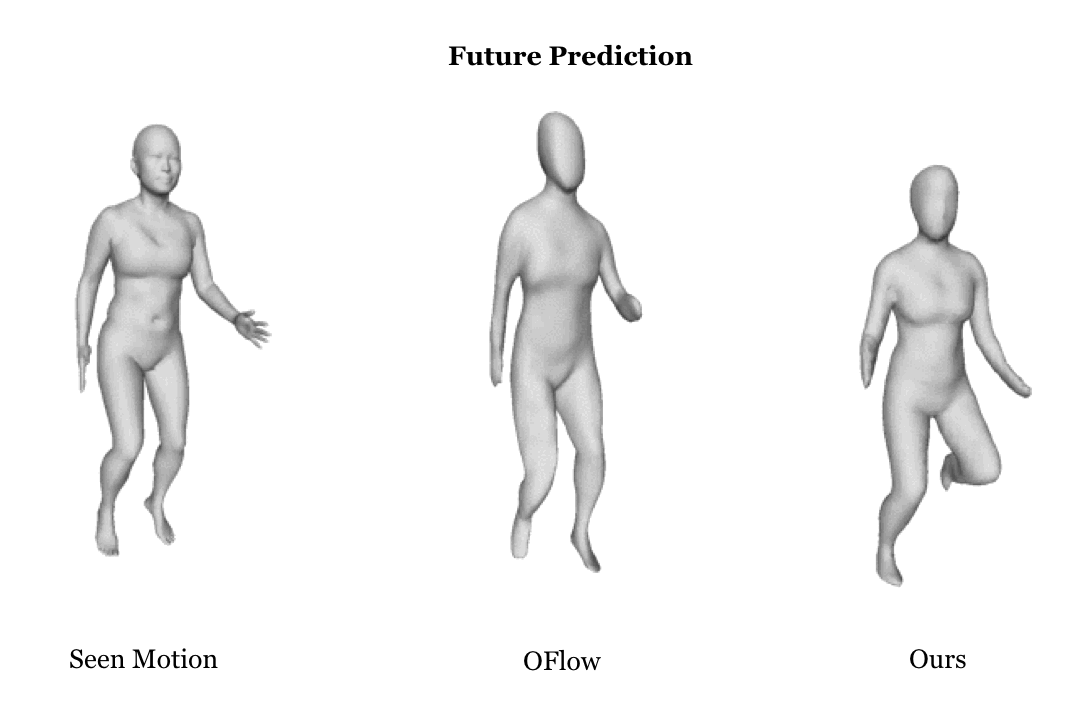
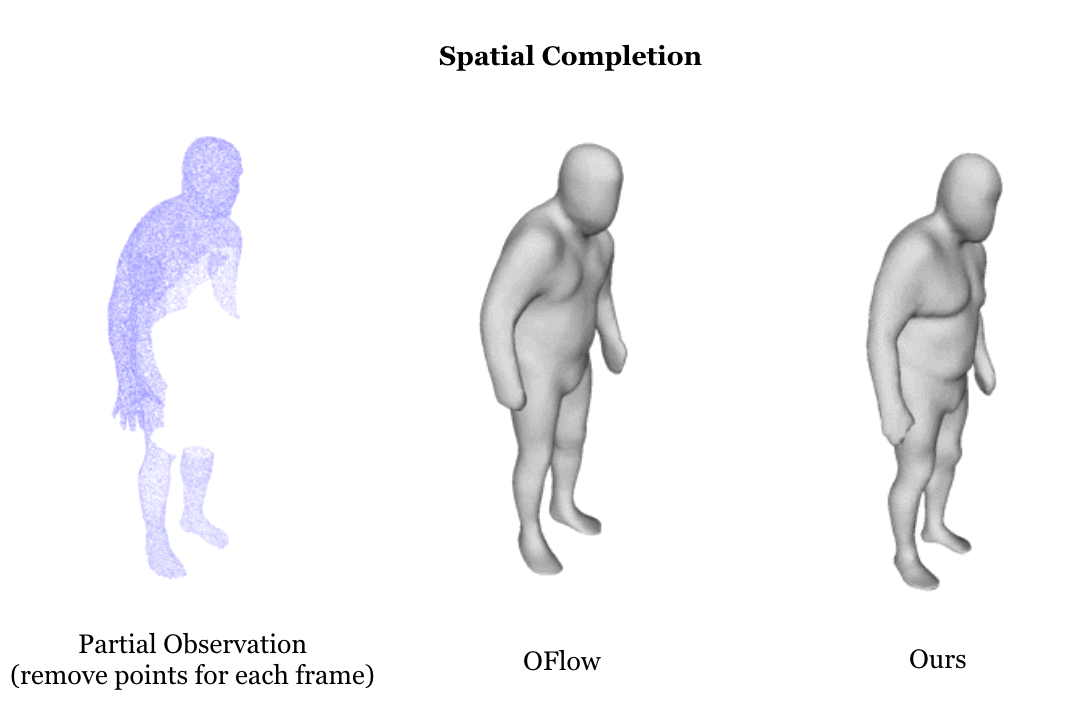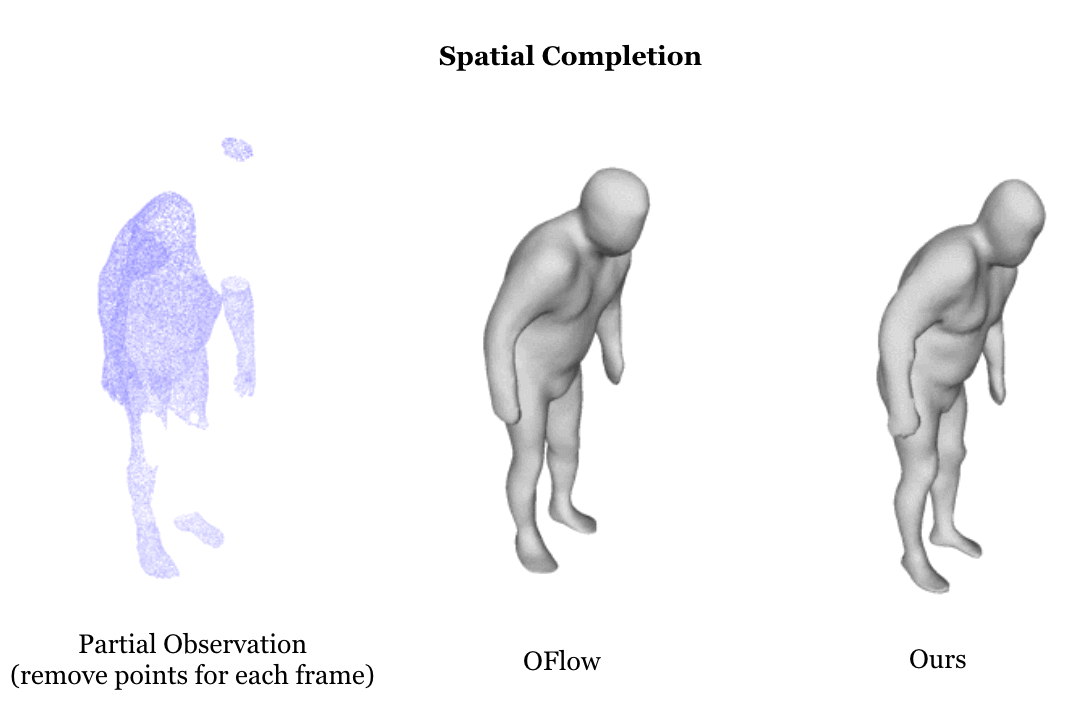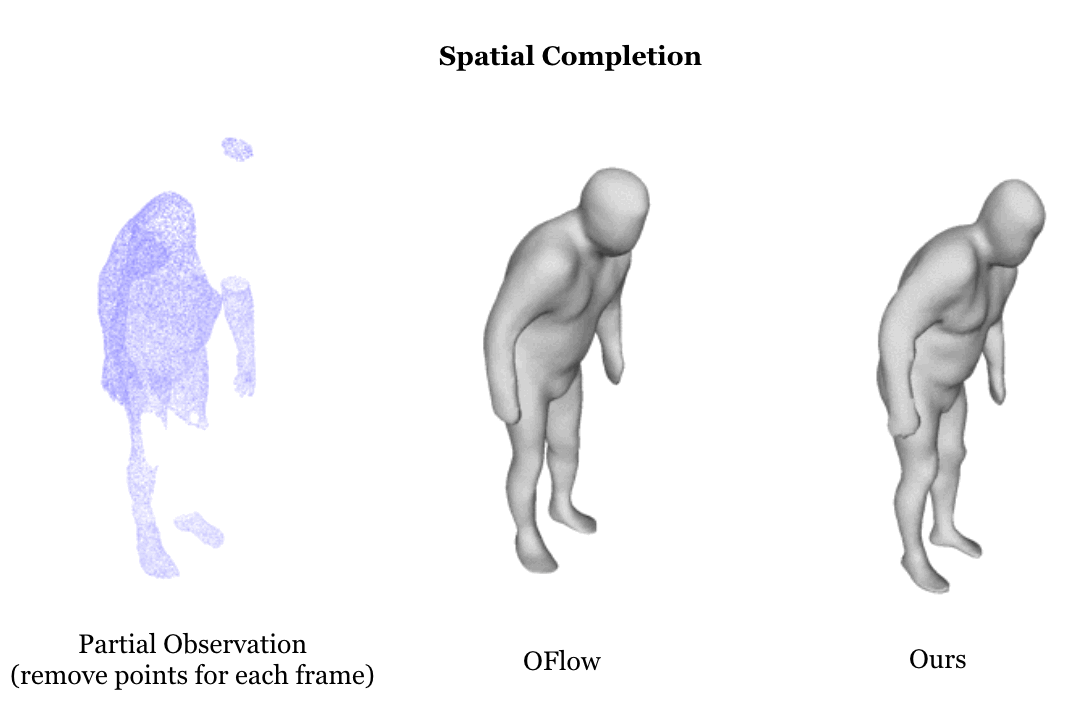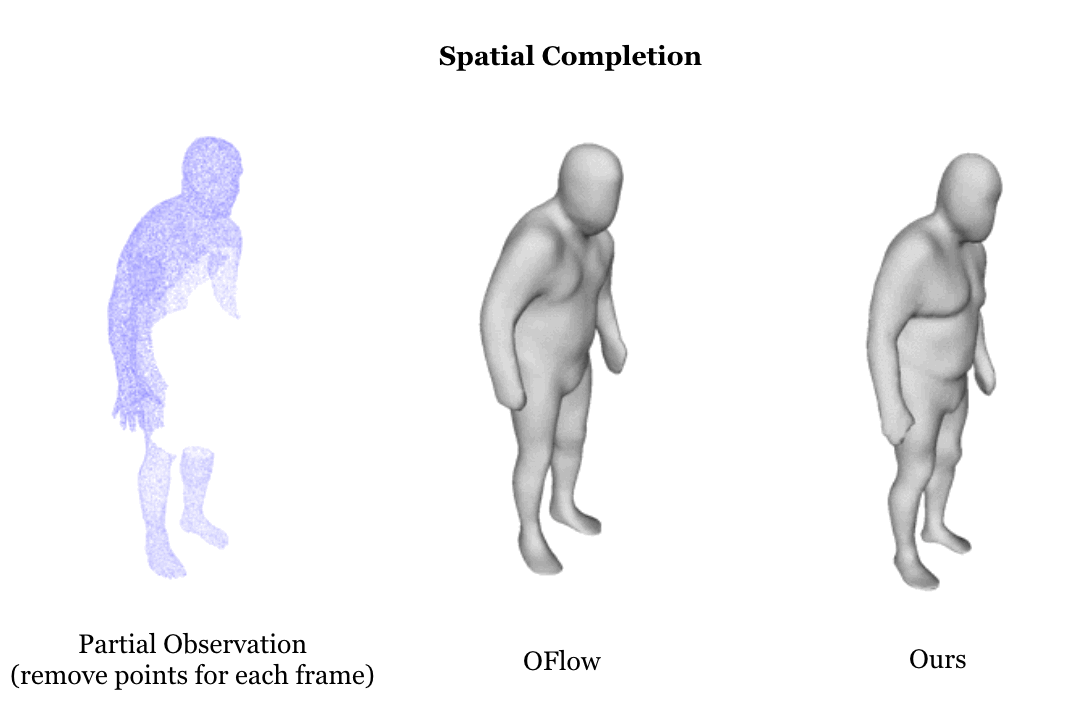
Learning based representation has become the key to the success of many computer vision systems. While many 3D representations have been proposed, it is still an unaddressed problem how to represent a dynamically changing 3D object. In this paper, we introduce a compositional representation for 4D captures, i.e. a deforming 3D object over a temporal span, that disentangles shape, initial state, and motion respectively. Each component is represented by a latent code via a trained encoder. To model the motion, a neural Ordinary Differential Equation (ODE) is trained to update the initial state conditioned on the learned motion code, and a decoder takes the shape code and the updated state code to reconstruct the 3D model at each time stamp. To this end, we propose an Identity Exchange Training (IET) strategy to encourage the network to learn effectively decoupling each component. Extensive experiments demonstrate that the proposed method outperforms existing state-of-the-art deep learning based methods on 4D reconstruction, and significantly improves on various tasks, including motion transfer and completion.

|
B. Jiang, Y. Zhang, X. Wei, X. Xue, Y. Fu
Learning Compositional Representation for 4D Captures with Neural ODE CVPR 2021. [arXiv] [GitHub] |
Video |
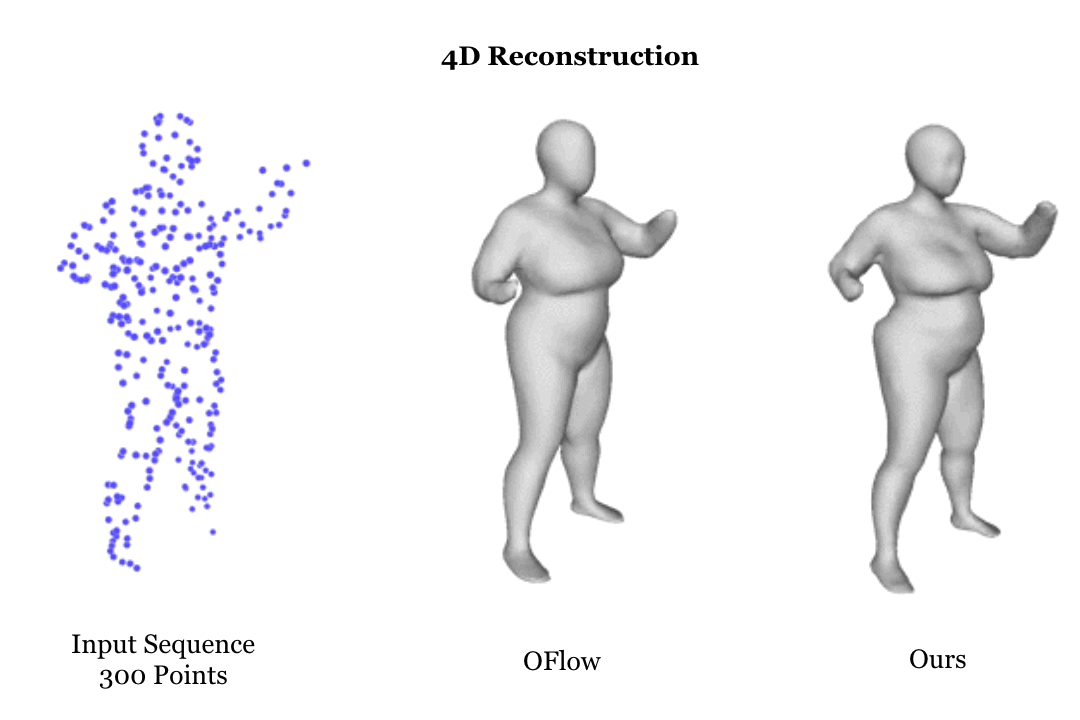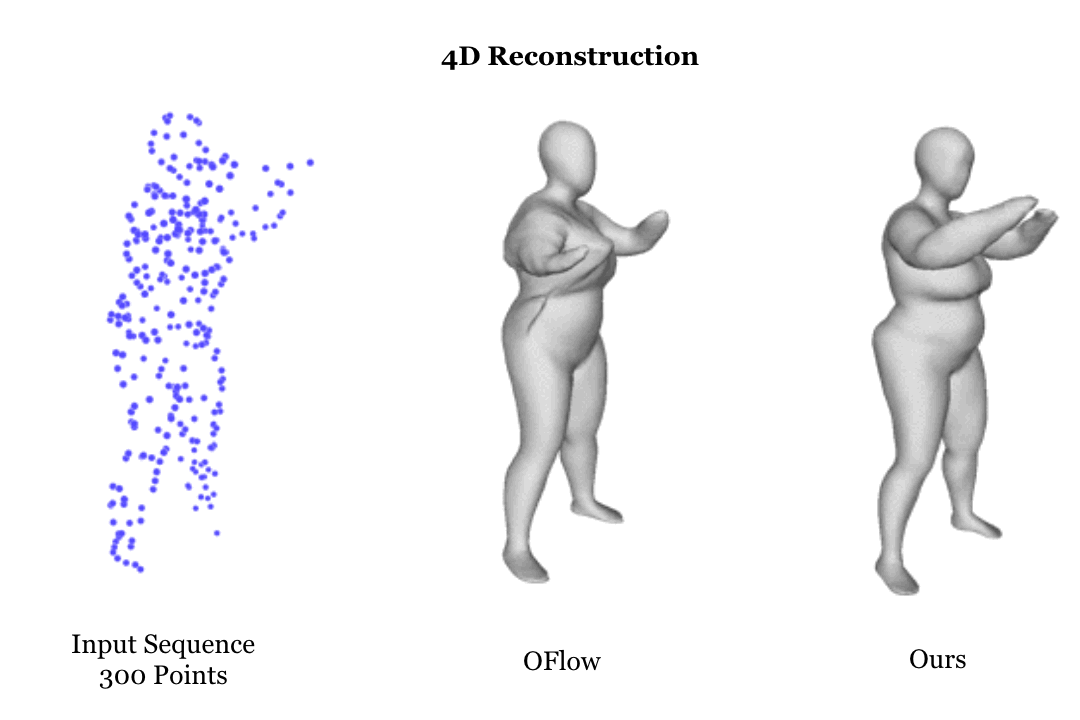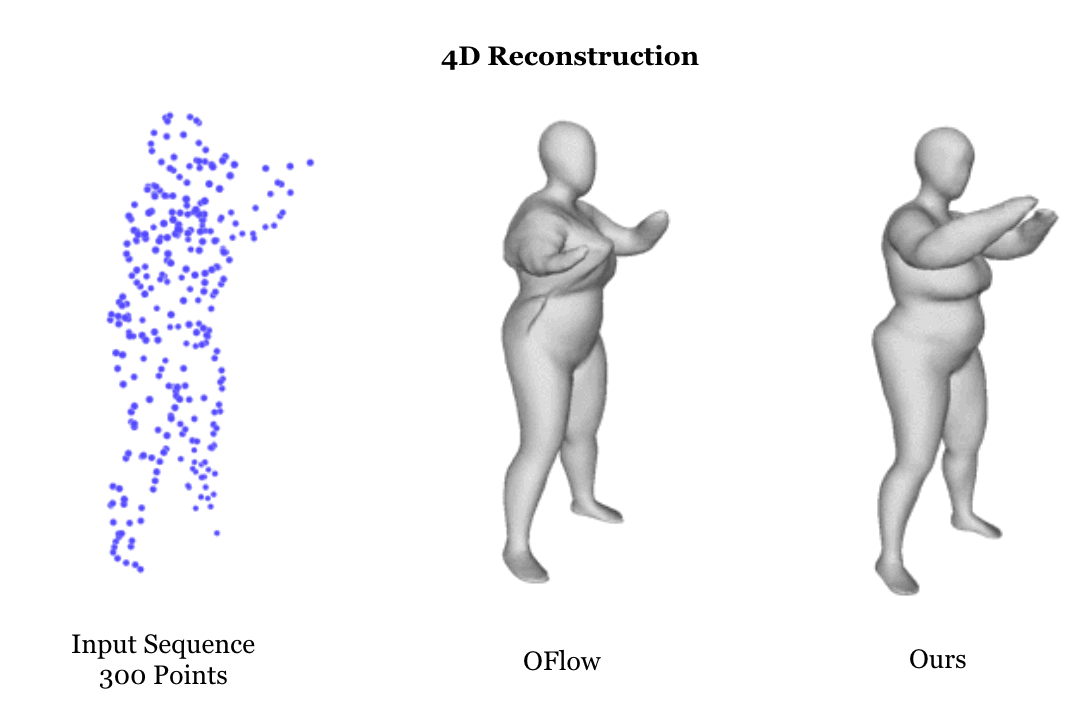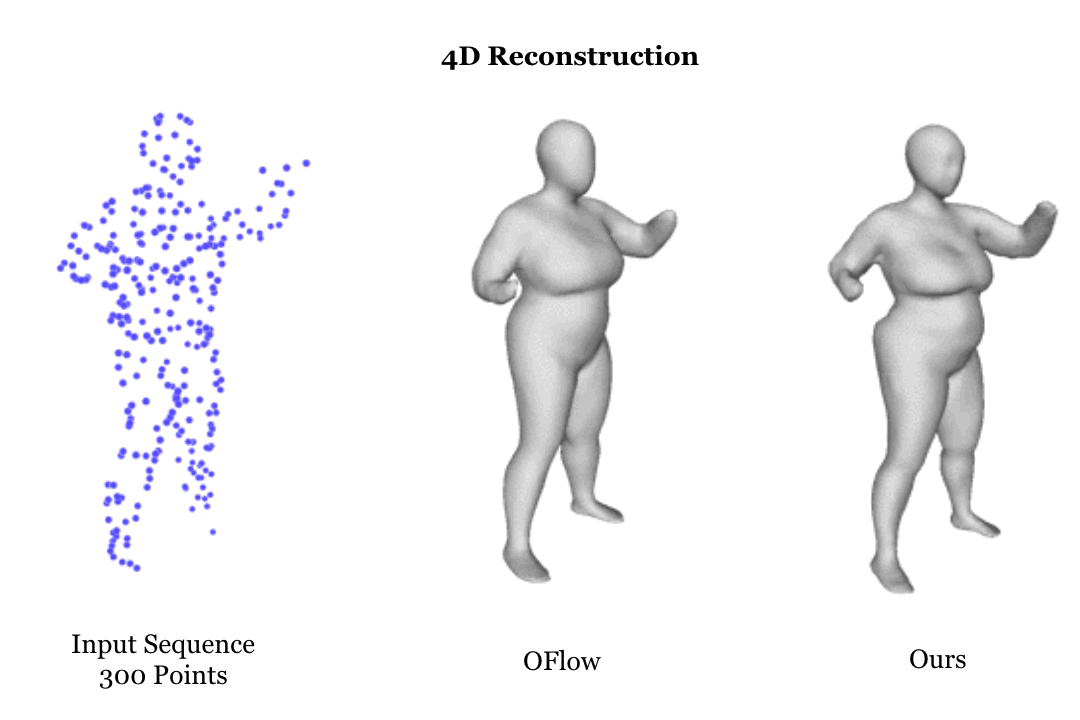  |
|
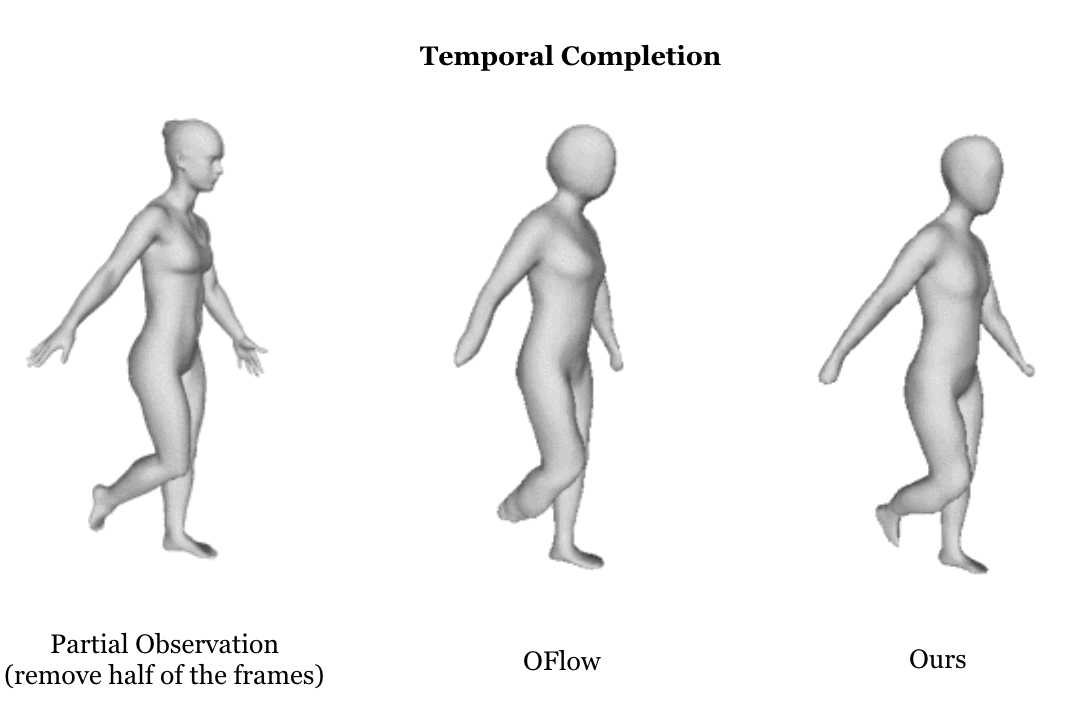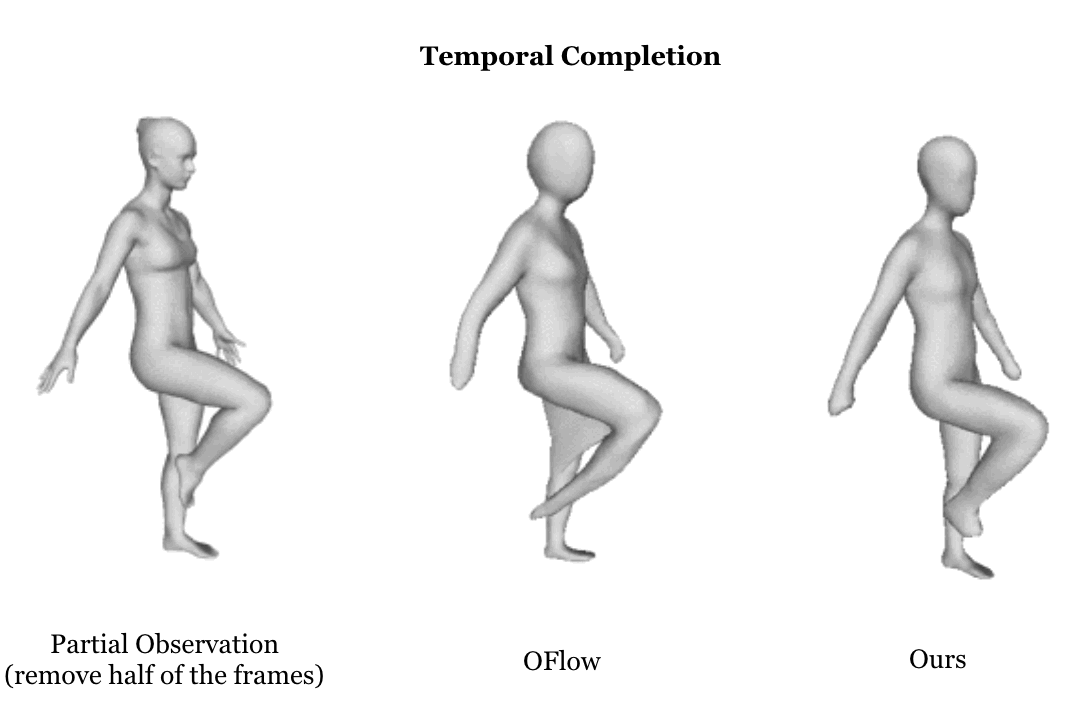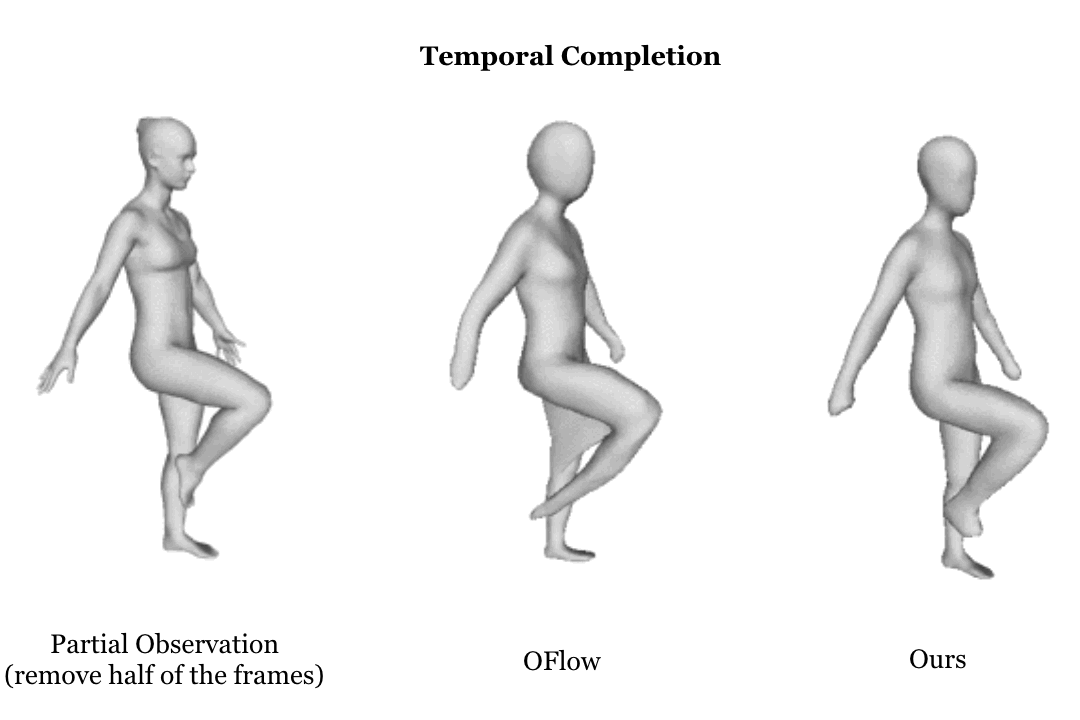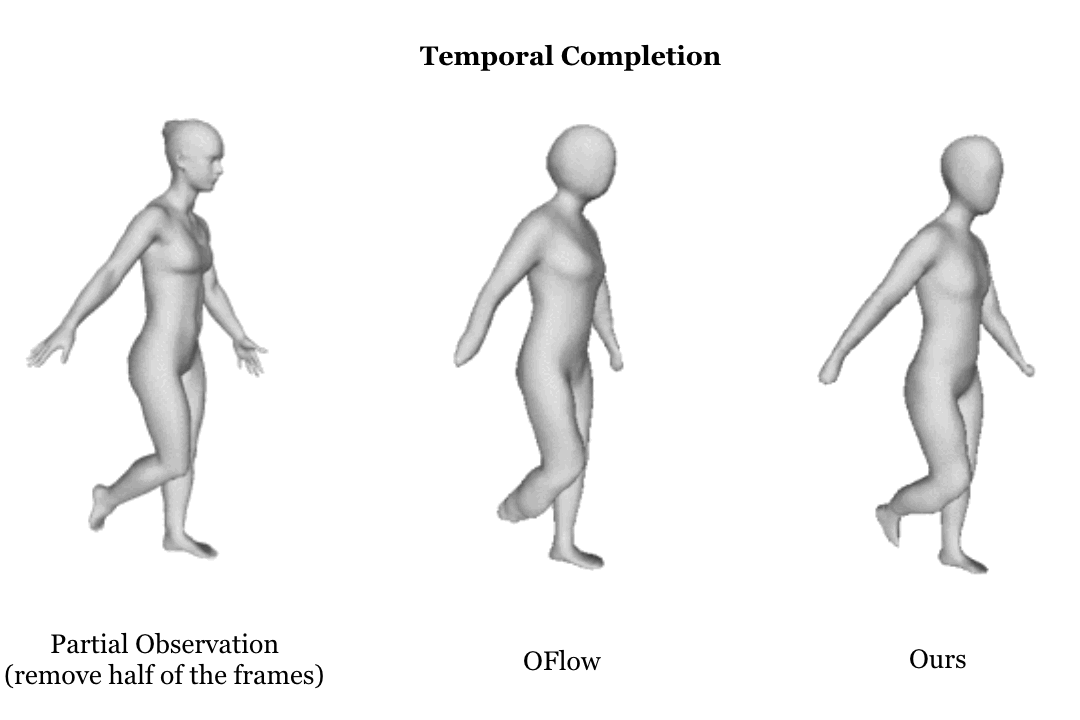  |
Acknowledgements
Yanwei Fu is the corresponding author. This work was supported in part by NSFC Projects (U62076067),
Science and Technology Commission of Shanghai Municipality Projects (19511120700, 19ZR1471800),
Shanghai Research and Innovation Functional Program (17DZ2260900),
Shanghai Municipal Science and Technology Major Project (2018SHZDZX01) and ZJLab.
The website is modified from this template.
|